



对PDF进行繁简体转换——OCR简体繁體使用教程
工具准备
所需工具
- OCR简体繁體识别软件:专门用于繁体中文OCR识别的软件
- Java运行环境:用于运行清理乱码的程序(JDK 8或以上版本)
- 文本编辑器:用于查看和编辑识别结果
软件获取
OCR简体繁體识别工具可以通过联系作者获取,本教程使用的是测试版本。
详细操作步骤
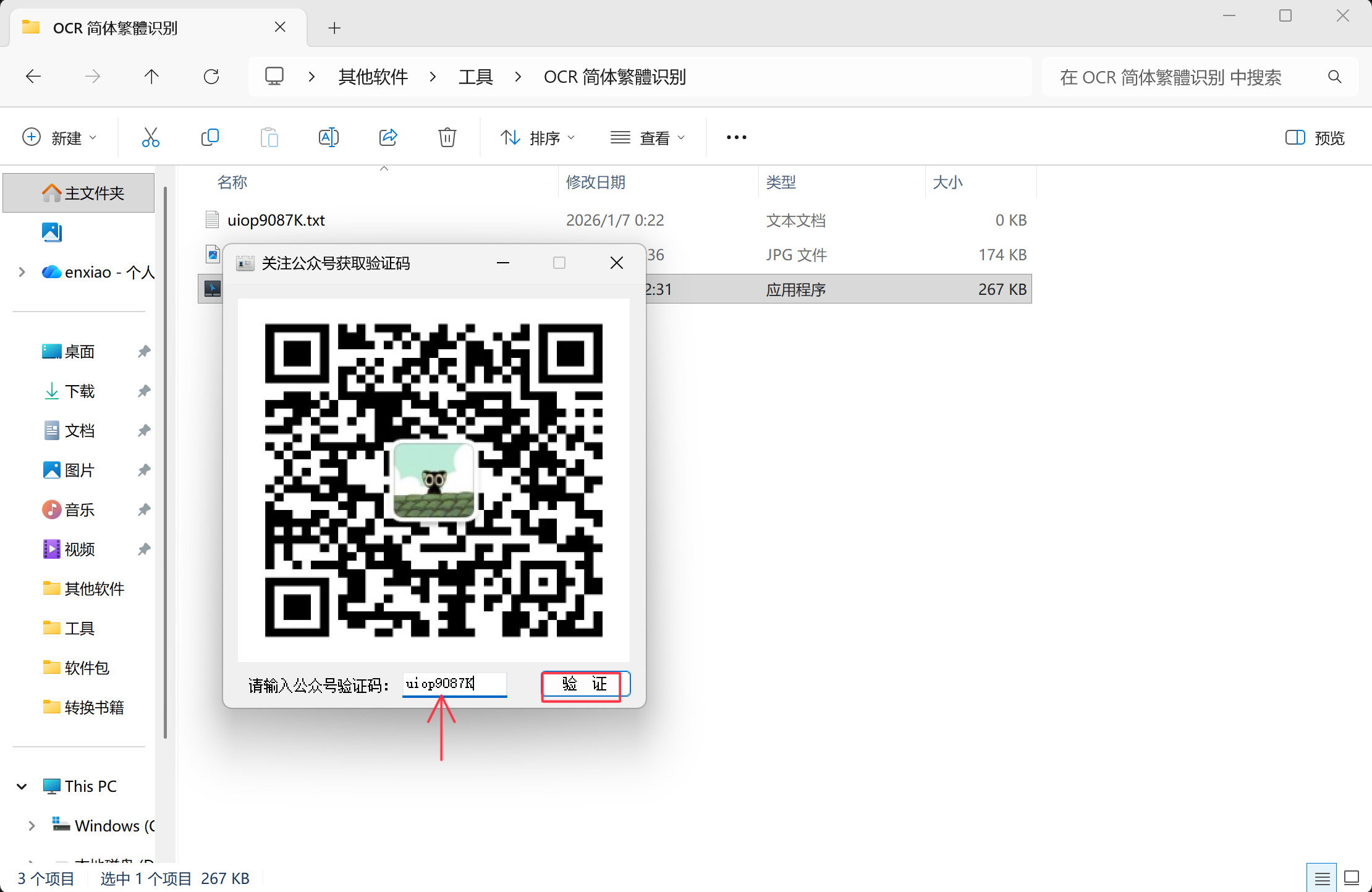
步骤1:启动OCR软件并验证
- 双击运行
OCR简体繁體识别.exe文件 - 在弹出的验证窗口中输入公众号验证码:uiop9087K
- 点击确认进入软件主界面
注意:该验证码仅适用于当前测试版本,正式版可能有所不同。
步骤2:导入需要识别的图片
- 在软件顶部的选项卡中点击"打开"按钮
- 在弹出的文件选择对话框中,选择包含繁体文字的图片文件
- 支持格式:JPG、PNG、BMP等常见图片格式
- 可以一次性选择多张图片进行批量处理
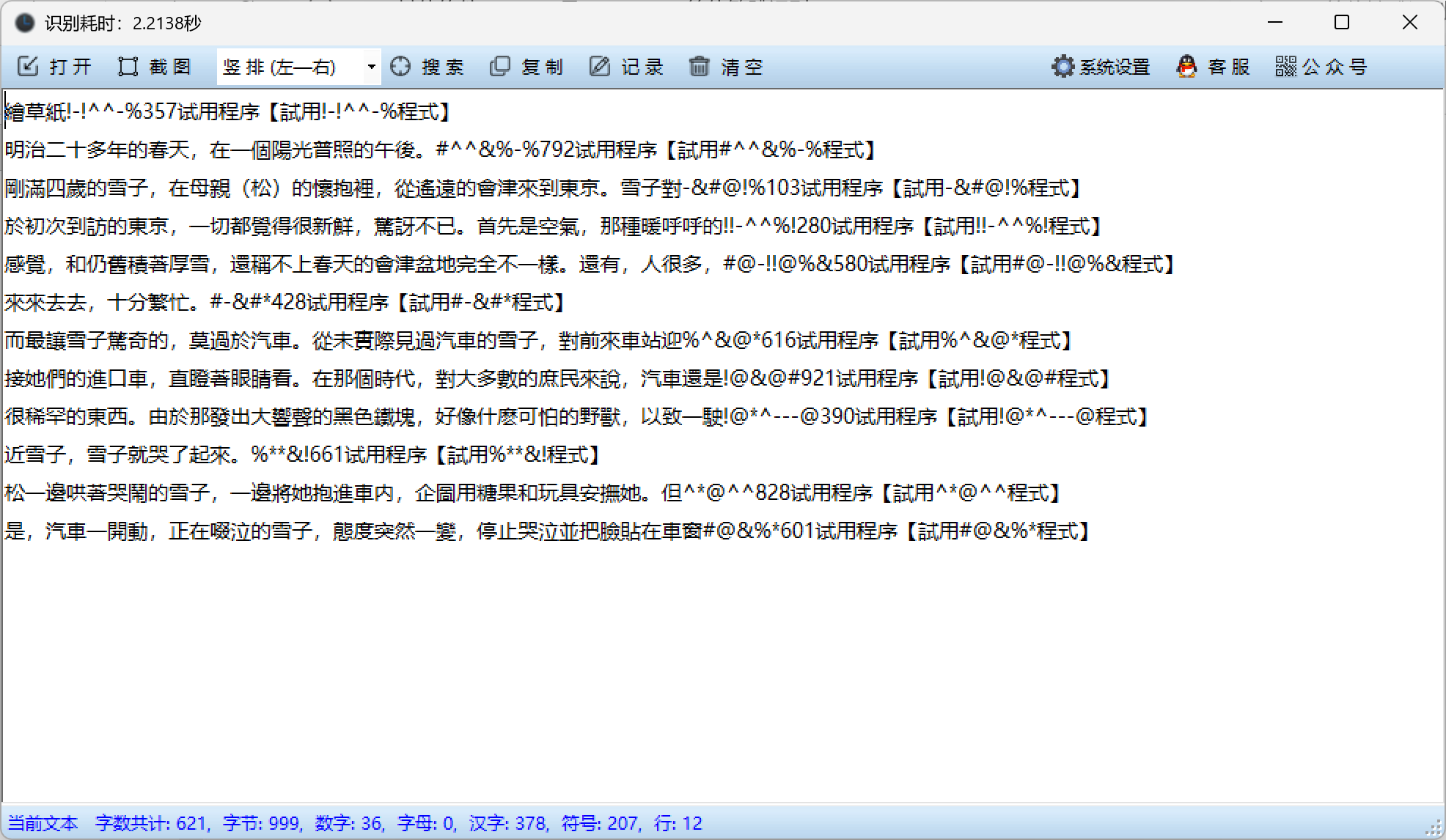
步骤3:自动识别文字内容
- 打开图片后,软件会自动进行OCR识别
- 识别过程通常需要几秒钟,取决于图片大小和文字数量
- 识别结果会显示在编辑框中
- 重要提示:由于是测试版软件,每行文字结尾可能会出现类似"xxx试用程序【试用xxx程式】"的乱码
步骤4:编辑和校对文本
- 在编辑框中可以直接修改识别错误的文字
- OCR识别可能存在误差,特别是对于:
- 手写体文字
- 低分辨率图片
- 特殊字体或艺术字
- 有背景干扰的文字
- 建议逐行检查并修正识别错误
- 可以利用软件的文本编辑功能进行复制、粘贴、查找等操作
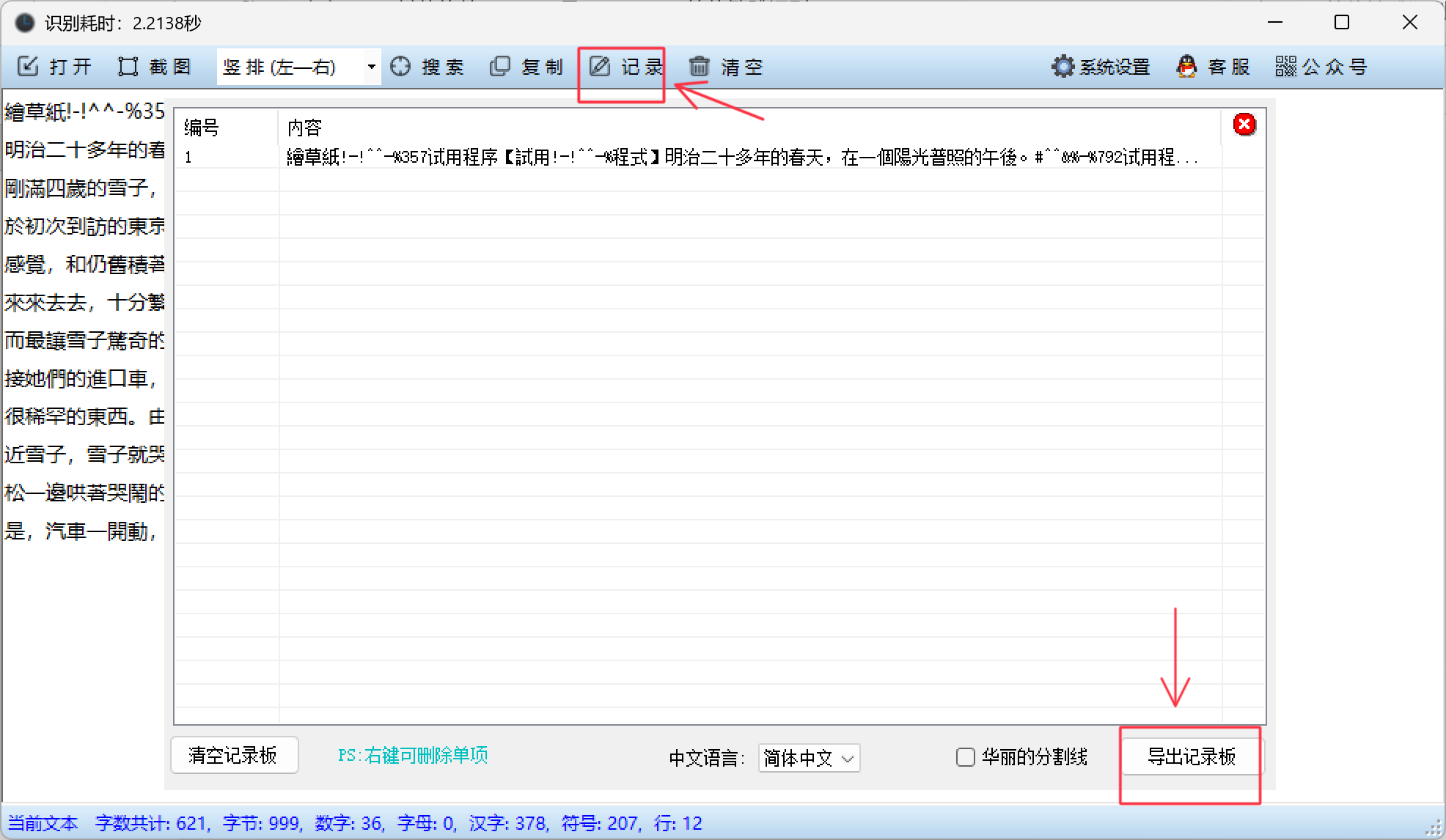
步骤5:使用记录板功能
- 点击选项卡中的"记录"按钮
- 系统弹出记录板窗口
- 可选择是否使用分割线
- 可以多次识别不同图片并添加到记录板
- 记录板支持查看本次历史识别记录
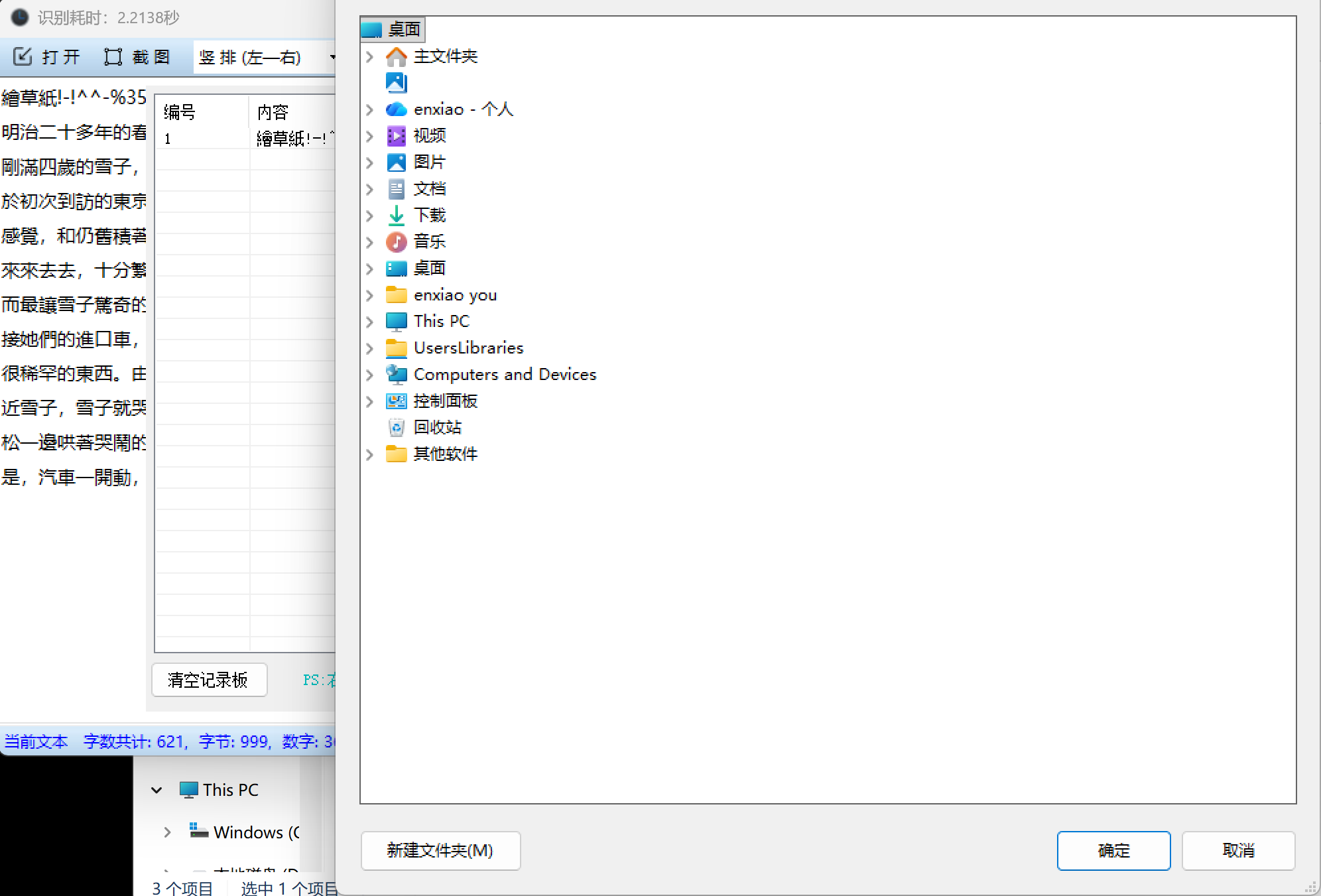
步骤6:导出识别结果
- 在记录板区域确认所有需要的内容都已添加
- 点击右下角的"导出记录板"按钮
- 选择保存位置和文件名
- 文件将以TXT格式保存
- 导出的文本文件包含所有识别记录,每段之间有空行分隔
解决乱码问题
问题描述
由于软件是测试版本,识别出的每行文字末尾会附加乱码字符串,格式为:
连续的符号 + 数字 + "试用程序【试用" + 符号 + "程式】"
例如:!@#916试用程序【试用!@#程式】
解决方案:使用Java程序清理乱码
准备工作
- 确保已安装Java运行环境(JDK 8或以上)
- 将下面的Java代码保存为
TextFileCleaner.java
Java清理程序代码
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.regex.*;
public class TextFileCleaner {
// 连续的符号集
private static final String SYMBOLS = ",.!?;:'\"()\\[\\]{}<>@#$%^&*+-=";
// 构建正则表达式模式
private static final Pattern PATTERN = Pattern.compile(
"[" + SYMBOLS + "]+\\d{3}试用程序【试用[" + SYMBOLS + "]+程式】$"
);
public static void main(String[] args) {
// 输入文件路径(修改为你的实际文件路径)
String inputFilePath = "C:\\Users\\你的用户名\\Downloads\\识别结果.txt";
// 输出文件路径
String outputFilePath = "C:\\Users\\你的用户名\\Downloads\\识别结果_清理后.txt";
try {
cleanTextFile(inputFilePath, outputFilePath);
System.out.println("文件处理完成!");
System.out.println("原始文件: " + inputFilePath);
System.out.println("处理后的文件: " + outputFilePath);
} catch (IOException e) {
System.err.println("处理文件时出错: " + e.getMessage());
e.printStackTrace();
}
}
/**
* 清理文本文件
* @param inputPath 输入文件路径
* @param outputPath 输出文件路径
* @throws IOException 如果文件读写出错
*/
public static void cleanTextFile(String inputPath, String outputPath) throws IOException {
// 使用UTF-8编码读取和写入,确保中文正常显示
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(inputPath), StandardCharsets.UTF_8));
BufferedWriter writer = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(outputPath), StandardCharsets.UTF_8))) {
String line;
int processedLines = 0;
int cleanedLines = 0;
while ((line = reader.readLine()) != null) {
processedLines++;
// 使用正则表达式匹配并删除末尾的乱码
String cleanedLine = removeSuffixPattern(line);
if (!line.equals(cleanedLine)) {
cleanedLines++;
}
// 写入清理后的行
writer.write(cleanedLine);
writer.newLine();
}
System.out.println("处理完成统计:");
System.out.println("总共处理行数: " + processedLines);
System.out.println("清理了乱码的行数: " + cleanedLines);
}
}
/**
* 删除行末尾的特定格式字符串
* @param line 原始行
* @return 清理后的行
*/
private static String removeSuffixPattern(String line) {
// 创建Matcher对象
Matcher matcher = PATTERN.matcher(line);
// 如果找到匹配的字符串,将其删除
if (matcher.find()) {
// 获取匹配的起始位置
int start = matcher.start();
// 保留匹配之前的部分
return line.substring(0, start);
}
// 如果没有匹配,返回原始行
return line;
}
}
使用步骤
修改文件路径:将代码中的
inputFilePath和outputFilePath修改为实际的文件路径编译程序:打开命令行,进入代码所在目录,执行:
javac TextFileCleaner.java运行程序:执行以下命令:
java TextFileCleaner查看结果:程序会在指定位置生成清理后的文本文件
高级技巧:正则表达式详解
// 正则表达式分解说明:
// [" + SYMBOLS + "]+ → 匹配一个或多个符号
// \\d{3} → 匹配三位数字
// 试用程序【试用 → 固定文字
// [" + SYMBOLS + "]+ → 再次匹配一个或多个符号
// 程式】$ → 以"程式】"结尾
如果需要处理不同的乱码模式,可以修改正则表达式中的相应部分。
注意事项
- 软件版本:本教程基于测试版软件,正式版可能已修复乱码问题
- 图片质量:识别准确率与图片质量密切相关,建议使用清晰、高分辨率的图片
- 文字校对:OCR识别后务必进行人工校对,特别是重要文档
- 文件备份:处理前请备份原始文件,以防数据丢失
- 编码问题:确保文本文件使用UTF-8编码,避免中文乱码
总结
通过本教程,您应该能够:
- 熟练使用OCR简体繁體识别工具进行文字识别
- 正确处理识别过程中的乱码问题
- 获得干净的繁体转简体中文文本
虽然过程中需要一些额外步骤来处理测试版的缺陷,但这种方法在暂时没有更好工具的情况下,仍然是一个有效的解决方案。

阅读建议


评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果
最新评论

A /

肖松 /

xx /